This is post 2 in the series on 'The 7 Data Habits of Highly Effective Product Companies'. Tune in to our LIVE WEBINAR '7 Data Habits of Successful Product Companies' - MARCH 31, 11 a.m. CDT

On any given day an organization runs a gauntlet that resembles solving a Rubik’s cube—multiple layers, sides, and colors all in motion, and all needing to fall into place simultaneously, in order to make timely and correct decisions. However, to do this having the right data is crucial to make the right determinations and take action. Today there is a deluge of data, and it continues to grow. This poses unique challenges, especially for engineers.
This flood of data has caused a plethora of new analytical tools and career paths to emerge that promise to harness the data and solve even the most challenging engineering and scientific problems. But, to truly exploit the power of data, every organization needs a sound strategy, and process, as well as the right tools.
New Data Challenges in Today’s Sensor-Centric World
Cross-industry studies show that on average, less than half of an organization’s structured data is actively used in making decisions—and less than 1% of its unstructured data is analyzed or used at all (Harvard Business Review).
We are experiencing a “Sensor Revolution.” New data streams from sensors are increasing exponentially. According to Accenture, more than 60 billion sensors are expected to be shipped worldwide this year. Any data user, manager of data, or executive whose business depends on data recognizes the importance of having a data strategy to meet this data challenge.
I first understood the value of a data strategy while working with a major jet engine company. I learned that the life span of a jet engine is an incredible 30 to 40 years. The team at this particular manufacturer was tasked with reducing the cost of test 50% by using untapped data collected over the years. So, how do you track down the information and knowledge gained over a 30 to 40 year lifespan? Forty years ago was before the commercialization of the Internet, it was prior to PCs and workstations, and cellphones didn’t exist either. So, what process and technology was used back then? Who were the people involved? Where was the data stored?
The common thread, that ties together the complex production of a jet engine over 40 years, is data. You can imagine that a vast amount of knowledge is gained over the years from building jet engines. Much of this knowledge fell under the umbrella of ‘tribal knowledge’. Amazingly they created an environment that was not always well understood but delivered engines that rarely failed. Employees and engineers during this era also stayed with the same company for their entire career. Today that workforce is graying and leaving, and the knowledge is walking out with them. The company recognized this fact, and it created a sense of urgency for better data management in hopes of capturing knowledge. In the final analysis, we recommended three things to the jet engine company to get the process rolling.

It turned out the lessons learned here were not unique to them. I saw this movie play out again and again at many different companies over the years. I identified four steps to consider when creating a data strategy.

Step 1 - Distill business impact
While this may seem obvious, it is the most common item I see companies gloss over. The urge is typically to go right to technology before fully understanding your data strategy's business impact. Three key areas to explore for business impact are:
- Reduction of R&D cost—How much time do people spend each week looking for data? Industry studies report that eight hours a week are wasted doing this simple task.
- Reducing analysis time—Look at your test cells. Are these being optimally utilized? Millions of dollars in equipment are deployed to do extensive test runs on engines. How long do the analytics cycles take? After test runs, data analysis takes place and test results are reported. If this is taking a considerable amount of time, millions of dollars in equipment could be lying idle. One company Viviota worked with was able to reduce their test analysis time from 10 hours to 10 minutes. This yielded significantly higher capital equipment optimization as well as labor savings.
- Data Forensics—A failure in the field can be costly and hard to diagnose. Looking at data based on an event and tracing the data back through the R&D process can speed this process. One company Viviota has helped reduced this factor from three weeks to one hour.
Step 2 - Create a vision (Turning data into knowledge)
For illustrative purposes, imagine knowledge as a sandpile. The sandpile is formed by adding one grain at a time. As the pile grows it forms a broad base and eventually becomes a nice, neat pile. Then, some of the sand is swept away or used to create a new pile. Genuinely great companies identify the critical data required for operations at the very top of the knowledge pile. They have developed systems to store, retrieve and, value data. While developing a strategy, ask these questions:
- How do we tap into the accumulated company knowledge?
- What insights might be extracted for the production process?
- How do we harness the power of this knowledge to drive automation and efficiency?
Remember to keep an eye on the big prize by linking the data to the company mission and business and not get distracted over-engineering. Keep it simple.
Step 3 - Inventory data assets (and place a value on them)
Most companies are very good at generating and acquiring all kinds of data. One company I worked with counted 5000+ sources of data! This situation arose gradually as the company product evolved. Point solutions were purchased for specific problems across the product lifecycle. For example, the engineers found they needed a CAD system, and inventory management found they needed a bill of materials. These systems started out independent of one another. The data from each phase of the product lifecycle is valuable. However, the real magic happens when data can be abstracted from multiple sources and used in collaboration across teams. The bottom line is data should be a first-class citizen and have a prominent place at the R&D table.
Step 4 - Make data a habit
Atomic Habits is a fantastic book by psychologist James Clear. In it he outlines the principles of making habits. He maps out an effective 4-step approach to creating a habit that he calls the ‘Four Laws of Behavior Change’. Clear aligns his Four Laws for creating new habits with this Habit Loop below.
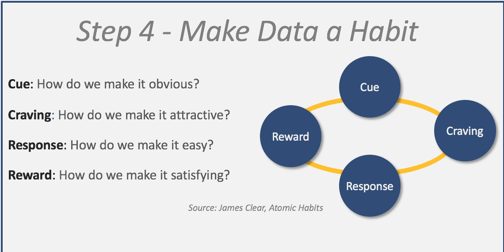
Drawing from this methodology, here are four lessons which can be applied to your data strategy:
- How to make data obvious—Data-centric thinking must be integral to all employees’ work. Start by linking the value of data to company results and measure it.
- How to make data attractive—This is connected to the craving. I relate this to the engineer who wants to work with data using the latest tools such as Python. Working with data may appeal to the technician who needs to improve the time it takes for root cause analysis.
- How to make data easy—Behaviors are more likely to be performed when they are comfortable. Map out the chain of actions a given end-user has to perform. Look at each stage of the process and ask how friction could be reduced for each task. Perhaps this can be automated; is this process really necessary?
- How to make data satisfying—If there is some reward associated with the behavior, then there is motivation to repeat it. For example, will frustration be reduced because data can be found more quickly?
A winning data strategy can be a competitive advantage. It can provide motivation to innovate. The winners in this high-stakes game have a plan that supports their business, which correctly values their data, and communicates value to all stakeholders, internally and externally.
Interested in Viviota hosting a workshop for your team? Please, reach out to me at barry.hutt@viviota.com to learn more. ![]()
Join our WEBINAR this Wednesday, March 31, 2021, 11 a.m. CDT '7 Data Habits of Successful Product Companies.'